The fastest AWS savings come from rightsizing EC2 and turning on the defaults nobody set: Reserved Instances for steady-state, S3 lifecycle policies, CloudWatch log retention, and VPC endpoints to dodge NAT egress. We took a $50k/month bill to $20k in six weeks with Terraform diffs and one Python script, no architecture rewrites and better p95 latency.
The CFO saw the AWS bill hit $50,000 a month and I got a calendar invite titled "We need to talk about AWS." I knew the meeting before I clicked accept.
Three months later we were at $20,000 a month, with better p95 latency than when we started. The interesting part is that none of the wins were clever. Most of them were a checkbox someone had skipped two years ago.
the starting point
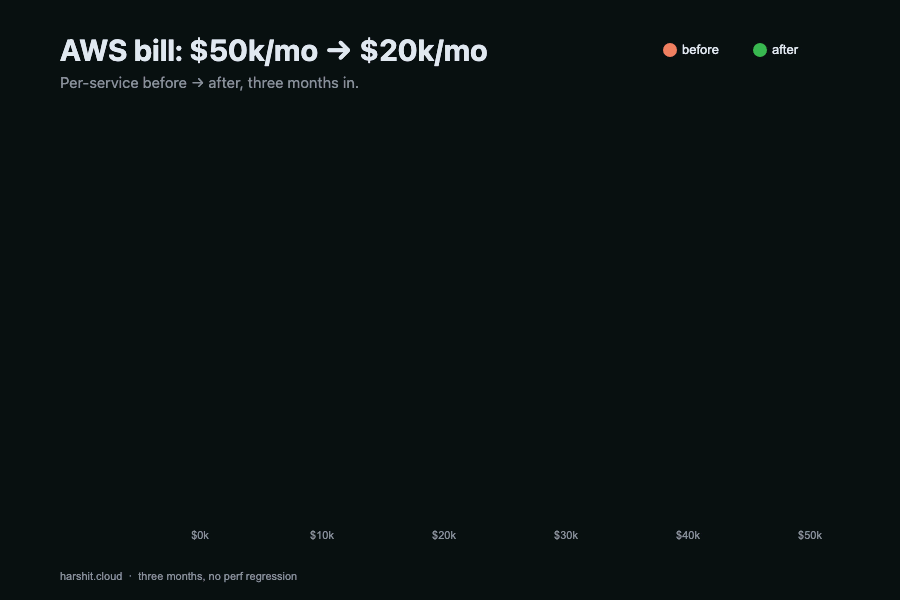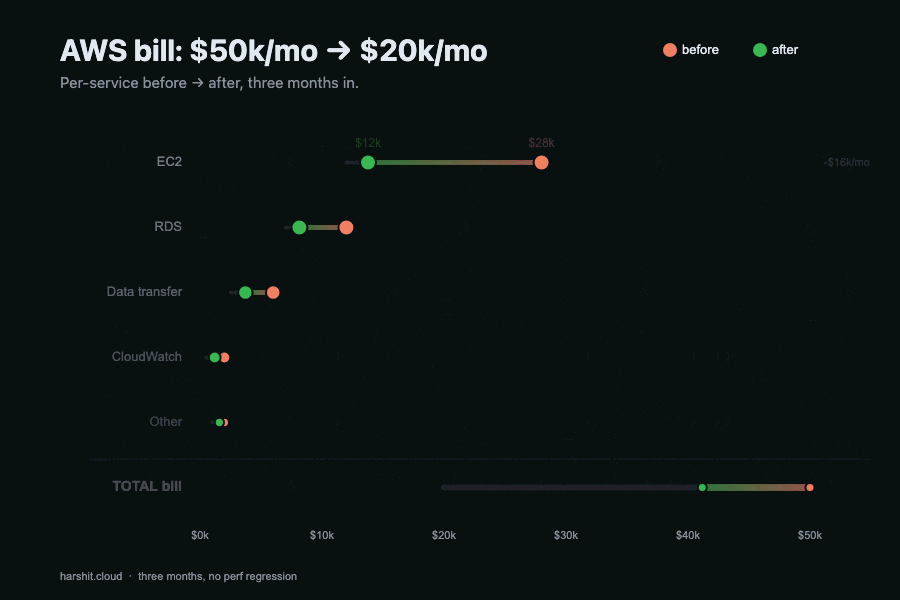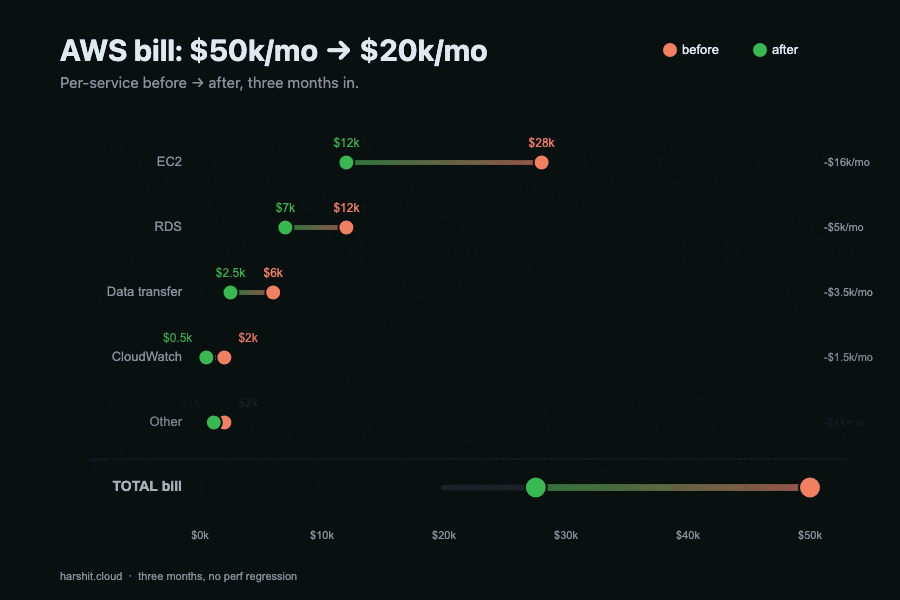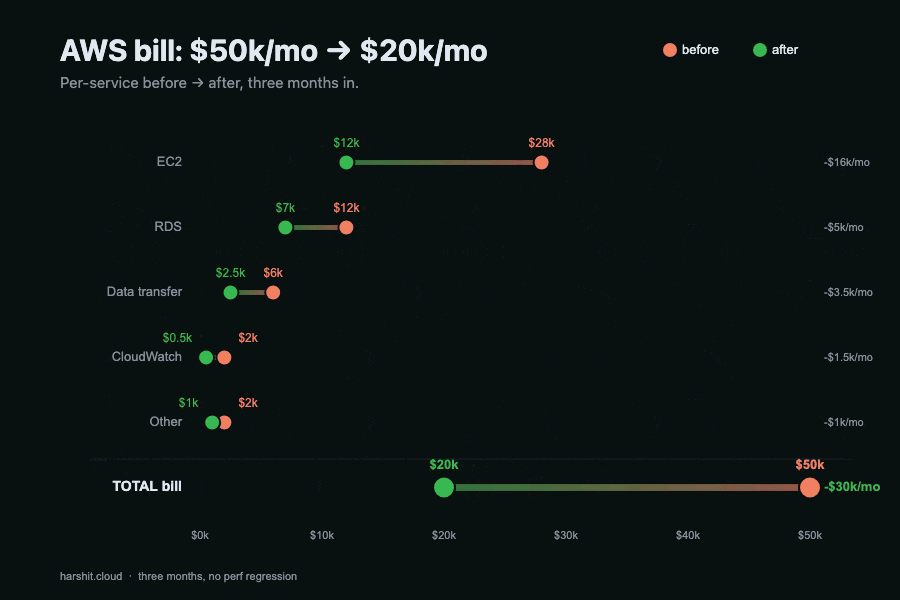
The bill broke down like this: EC2 $28,000, RDS $12,000, data transfer $6,000, CloudWatch $2,000, everything else $2,000. Fifty grand a month. The cost-allocation tags were missing on roughly 40% of resources, so for the first week the work was just figuring out who owned what.
Most of it turned out to be waste. Not bad architecture, not premature scale, just defaults that nobody had revisited since the seed round.
rightsizing the EC2 fleet
Every app server in the fleet was running on m5.2xlarge. Not because anything needed eight vCPUs, but because the previous engineer picked an instance type once in 2022 and Terraform copy-pasted it forever after.
A month of CloudWatch told the real story:
# Check actual CPU utilization
aws cloudwatch get-metric-statistics \
--namespace AWS/EC2 \
--metric-name CPUUtilization \
--dimensions Name=InstanceId,Value=i-xxxxx \
--start-time 2024-01-01T00:00:00Z \
--end-time 2024-01-31T23:59:59Z \
--period 3600 \
--statistics AverageAverage CPU 12%. Average memory 30%. The fleet was a parking lot.
Dropping to m5.large cut the per-hour rate by 4x:
# Before
resource "aws_instance" "app" {
instance_type = "m5.2xlarge" # $0.384/hour
}
# After
resource "aws_instance" "app" {
instance_type = "m5.large" # $0.096/hour
}That single change saved $18,000 a month. p95 latency went down because the new instances were on a newer hypervisor generation. (I have stopped being surprised by this.)
reserved instances for the steady-state fleet
The app servers ran 24/7. We were paying On-Demand for them anyway, because nobody had wanted to commit a year ahead during a hiring freeze.
The Cost Explorer recommendation API will tell you what to buy if you ask it nicely:
aws ce get-reservation-purchase-recommendation \
--service "Amazon Elastic Compute Cloud - Compute" \
--lookback-period-in-days SIXTY_DAYS \
--term-in-years ONE \
--payment-option ALL_UPFRONTWe bought 1-year RIs for ten m5.large app servers and five c5.xlarge API servers. 40% off On-Demand, no architectural change, no risk. $4,000 a month back.
The argument against RIs is always "but what if our load profile changes." Three months later it hadn't.
spot for the things that can die
The CI fleet was On-Demand c5.xlarge runners that sat idle most of the day and got hammered for an hour around lunch. A perfect Spot workload: interruptible, parallelizable, with a queue in front.
resource "aws_launch_template" "ci_runner" {
name_prefix = "ci-runner-"
image_id = data.aws_ami.ubuntu.id
instance_type = "c5.xlarge"
instance_market_options {
market_type = "spot"
spot_options {
max_price = "0.10" # ~70% discount
spot_instance_type = "one-time"
instance_interruption_behavior = "terminate"
}
}
}
resource "aws_autoscaling_group" "ci_runners" {
name = "ci-runners"
mixed_instances_policy {
launch_template {
launch_template_specification {
launch_template_id = aws_launch_template.ci_runner.id
}
}
instances_distribution {
on_demand_base_capacity = 1 # one runner always on
on_demand_percentage_above_base_capacity = 0 # everything else is Spot
spot_allocation_strategy = "capacity-optimized"
}
}
min_size = 2
max_size = 10
}One On-Demand runner for the always-on baseline, the rest Spot, capacity-optimized strategy so AWS picks pools with low interruption rates. $2,500 a month. The CI team noticed the build queue was faster, not that the underlying instances had changed.
S3 lifecycle policies
We had 50 TB in S3, all in Standard. The application logs were the worst offender: every JSON line our services had ever emitted, sitting at $0.023 per GB-month, being read by exactly nobody.
aws s3api list-objects-v2 \
--bucket my-bucket \
--query "Contents[?LastModified<'2023-01-01'].[Key,Size]" \
--output tableMost of it hadn't been touched in a year.
The lifecycle policy is the thing AWS lets you write once and forget:
{
"Rules": [
{
"Id": "Archive old logs",
"Status": "Enabled",
"Filter": { "Prefix": "logs/" },
"Transitions": [
{ "Days": 30, "StorageClass": "STANDARD_IA" },
{ "Days": 90, "StorageClass": "GLACIER_IR" },
{ "Days": 180, "StorageClass": "DEEP_ARCHIVE" }
]
},
{
"Id": "Delete old temp files",
"Status": "Enabled",
"Filter": { "Prefix": "temp/" },
"Expiration": { "Days": 7 }
},
{
"Id": "Intelligent tiering for backups",
"Status": "Enabled",
"Filter": { "Prefix": "backups/" },
"Transitions": [
{ "Days": 0, "StorageClass": "INTELLIGENT_TIERING" }
]
}
]
}Apply it once:
aws s3api put-bucket-lifecycle-configuration \
--bucket my-bucket \
--lifecycle-configuration file://lifecycle.json$3,000 a month. The work was reading enough of the data to be confident no on-call runbook secretly depended on a five-year-old log line. (One did. We rewrote the runbook.)
RDS, where the real fat lived
The dev database was a db.r5.4xlarge. Sixteen vCPUs and 128 GB of RAM, running 24/7, used by maybe three engineers between 10am and 6pm in one timezone. It cost more than half the engineering team's laptops combined.
The fix was three changes. Drop the dev instance to db.t3.large. Auto-stop it at night and on weekends. Move staging to Aurora Serverless v2 so it scales to half a capacity unit when idle:
resource "aws_db_instance" "dev" {
identifier = "dev-database"
instance_class = "db.t3.large" # was db.r5.4xlarge
iam_database_authentication_enabled = true
auto_minor_version_upgrade = true
backup_retention_period = 7
backup_window = "03:00-04:00"
maintenance_window = "mon:04:00-mon:05:00"
}
resource "aws_rds_cluster" "staging" {
cluster_identifier = "staging-aurora"
engine = "aurora-postgresql"
engine_mode = "provisioned"
serverlessv2_scaling_configuration {
max_capacity = 2.0
min_capacity = 0.5
}
}$5,000 a month. The complaints about staging being slow on the first request after lunch went away once people understood that two seconds of cold-start was the trade.
CloudWatch, where ingestion is the real bill
CloudWatch costs split three ways: ingestion ($0.50 per GB), storage ($0.03 per GB-month), and analysis. For us, ingestion was the biggest line by far, and the default of "never expire" meant we were also paying to keep a stack trace from 2021 forever. Four levers, biggest first.
Filter verbose logs before they're ingested. Half our ingestion was INFO and DEBUG lines from happy-path requests in production. A subscription filter that drops them at the log group, or just raising the app log level in prod, cut ingestion volume by more than 50%. You pay for every GB that lands, so the cheapest log line is the one you never send.
Set retention on every log group. A short script walked the whole account:
import boto3
client = boto3.client('logs')
paginator = client.get_paginator('describe_log_groups')
for page in paginator.paginate():
for log_group in page['logGroups']:
group_name = log_group['logGroupName']
# prod keeps 30 days, everything else keeps 7
retention_days = 30 if 'prod' in group_name else 7
client.put_retention_policy(
logGroupName=group_name,
retentionInDays=retention_days,
)
print(f"Set {group_name} to {retention_days} days")Use the Infrequent Access log class for logs you rarely query. Logs you keep for audit or the occasional incident, but don't run Logs Insights against daily, can go in the Infrequent Access class. Ingestion lands at roughly half the Standard rate. You give up some advanced query features, which for cold audit logs you weren't using anyway.
Consolidate dashboards and watch cardinality. Each dashboard is $3/month, so one dashboard per service with several widget rows beats a separate dashboard per metric. And high-cardinality custom metrics, the ones tagged with per-request dimensions like RequestId or UserId, each count as a distinct metric and add up fast. Aggregate before you publish.
$1,500 a month, recovered from log groups whose entire purpose was to exist.
the NAT gateway tax
Three NAT Gateways, one per AZ, $0.045 per hour each. The HA story was airtight. The actual traffic profile didn't justify it for the non-prod VPCs.
# Before: 3 NAT Gateways
resource "aws_nat_gateway" "az1" { /* ... */ }
resource "aws_nat_gateway" "az2" { /* ... */ }
resource "aws_nat_gateway" "az3" { /* ... */ }
# After: 1 NAT Gateway
resource "aws_nat_gateway" "main" {
allocation_id = aws_eip.nat.id
subnet_id = aws_subnet.public[0].id
tags = { Name = "main-nat-gateway" }
}
resource "aws_route" "private_nat" {
for_each = aws_route_table.private
route_table_id = each.value.id
destination_cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.main.id
}$200 a month. We kept the three-gateway HA setup in production. The argument against single-NAT in dev is "but what if the AZ goes down?" The answer in dev is "then dev is down."
data transfer, the silent killer
$6,000 a month in data transfer fees, which is the kind of bill where you can't actually see what you're paying for until you turn on VPC Flow Logs and read them.
aws ec2 create-flow-logs \
--resource-type VPC \
--resource-ids vpc-xxxxx \
--traffic-type ALL \
--log-destination-type s3 \
--log-destination arn:aws:s3:::my-flow-logsTwo culprits. App servers were pulling Docker images from external registries on every cold start, paying NAT egress on every layer. And one stale cron job was syncing a database snapshot across regions every hour for a use case that nobody could remember sponsoring.
ECR interface endpoints route the registry traffic privately, so it never leaves the VPC and never touches NAT:
resource "aws_vpc_endpoint" "ecr_api" {
vpc_id = aws_vpc.main.id
service_name = "com.amazonaws.us-east-1.ecr.api"
vpc_endpoint_type = "Interface"
private_dns_enabled = true
subnet_ids = aws_subnet.private[*].id
security_group_ids = [aws_security_group.vpc_endpoints.id]
}
resource "aws_vpc_endpoint" "ecr_dkr" {
vpc_id = aws_vpc.main.id
service_name = "com.amazonaws.us-east-1.ecr.dkr"
vpc_endpoint_type = "Interface"
private_dns_enabled = true
subnet_ids = aws_subnet.private[*].id
security_group_ids = [aws_security_group.vpc_endpoints.id]
}The S3 gateway endpoint is free, which is the only kind of free that AWS hands out without an asterisk:
resource "aws_vpc_endpoint" "s3" {
vpc_id = aws_vpc.main.id
service_name = "com.amazonaws.us-east-1.s3"
route_table_ids = aws_route_table.private[*].id
}CloudFront went in front of the static asset bucket, which moved bytes out of the per-GB egress lane and into the CDN lane. $3,500 a month back, most of which was the ECR change alone.
budgets, so the next surprise isn't a surprise
The reason this whole exercise happened in the first place was that nobody had a budget alert. The fix is twelve lines of Terraform:
resource "aws_budgets_budget" "monthly" {
name = "monthly-budget"
budget_type = "COST"
limit_amount = "25000"
limit_unit = "USD"
time_unit = "MONTHLY"
notification {
comparison_operator = "GREATER_THAN"
threshold = 80
threshold_type = "PERCENTAGE"
notification_type = "ACTUAL"
subscriber_email_addresses = ["alerts@company.com"]
}
notification {
comparison_operator = "GREATER_THAN"
threshold = 100
threshold_type = "PERCENTAGE"
notification_type = "FORECASTED"
subscriber_email_addresses = ["cfo@company.com"]
}
}The CFO gets the forecasted-overshoot alert. The on-call gets the 80%-of-actual alert. By the time the second one fires, somebody is already digging.
the receipts
| Category | Before | After | Savings |
|---|---|---|---|
| EC2 | $28,000 | $12,000 | 57% |
| RDS | $12,000 | $7,000 | 42% |
| Data Transfer | $6,000 | $2,500 | 58% |
| CloudWatch | $2,000 | $500 | 75% |
| Other | $2,000 | $1,000 | 50% |
| Total | $50,000 | $20,000 | 60% |
Six weeks of part-time work, no architecture rewrites, no migrations, no vendor changes. Mostly Terraform diffs and one Python script.
The line from the postmortem the CFO actually circulated was the part I keep coming back to: "The bill didn't grow because we scaled. The bill grew because nobody was looking."